デジタルの世界
活版印刷の衰退とともに、鉛合金活字の世界はデジタル・フォントの世界に置き換えられつつある。しかし、用字数の限られた欧米系諸言語圏の場合と違って、使用する漢字や仮名が膨大な数にのぼる日本語の場合、文字のデジタル化には字体の収集、字母の作成、コードの設定など克服すべき多くの課題が待ち受けている。文字は「刷る」ものでなくなり「出力する」ものであるという認識が広く一般社会に根を下ろしたとき、われわれはどのような眼差しで「歴史の文字」を顧みることになるのだろうか。
デジタル・ミュージアムと文字
坂村 健
マルチメディアやインターネットといったコンピュータ技術の普及により、コンテンツの重要性が急激にクローズアップされている。膨大な「東京大学コレクション」は、まさにコンテンツの宝庫である。
そのコンテンツを最新のコンピュータ技術でデジタル化することにより、博物館の持つ資料の保存・整理公開の機能に新しい地平を開く、はじめての「デジタル・ミュージアム」となることを「東京大学総合研究博物館」は目指している。
デジタル・アーカイヴ
デジタル・ミュージアムとは、まず第一に資料をデジタルアーカイヴするミュージアムである。従来の紙ベースの資料や写真は、年月により劣化し、情報が失われてしまう。それらの劣化しやすい資料も、デジタル化し記録することにより半永久的に保存可能な情報資料にすることができる。
さらに紙のような二次元資料でない、壷や人骨などの実物資料も、レーザー利用の三次元デジタイザや各種のセンサーにより、様々なデータの集合体として表現できる。
例えば一つの壼は、三次元デジタイズ・データ、CADデータ、表面のテクスチャ・データといった外観再現用のデータだけでなく、X線CTのデータや、釉薬の化学分析データ、さらには図案の解説から、制作手法に関する分析まで、さまざまなデータが結びつけられ、それらのデータ群全体が関連しあった実体としてデータベースの中に「収蔵」されるのである。
このように資料を精緻に電子化することにより、オリジナルの資料へのアクセスの必要性を減らすことができ、オリジナルを徹底的な保存管理下におけるので、将来的にも資料の傷みを最小限にすることが可能になる。
マルチメディア・プレゼンテーション
次にデジタル・ミュージアムとは、目で見るだけでないミュージアムである。視覚情報によりかかってきた従来の博物館の枠を越えて、聴覚やさらには触覚など、広い感覚──マルチメディアで資料を「公開」する。
各所に情報端末をおき観覧者の関心の流れにそって変化する展示を行ったり、個々人の必要に応じて、使用言語を他国語に変えたり、動画像から音声までマルチメディアを利用した解説を行ったりといったことを行う。無線によってネットワーク接続する携帯型の情報端末を利用者が持ち歩くことで、館内のどこでも自由に情報検索が可能となる。
また、視覚、聴覚だけでなく、触覚による展示のためにレプリカ作製装置がある。これによりデジタル・アーカイヴに「収納」した立体資料を、レプリカとして「取り出す」ことができる。簡単に再生可能なレプリカなら、資料の破損を恐れずに自由に触ってもらえる。さらに、博物館館内やレプリカなどに各種のセンサーとコンピュータを仕込むことで、それ自身が質問に答える展示物や、注目されている部位に合せてより細かい解説を行う展示物、樹脂のレプリカが叩かれたときに陶器の硬質の音を返すといった一種のシミュレーションなども可能になる。
このようなマルチメディア展示能力は一般の人の理解を助けると同時に、いままで博物館の恩恵を受けられなかった様々な障害を持つ人々にも門戸を開くことにつながる。
ヴァーチャル・ミュージアム
そしてデジタル・ミュージアムでは、展示室で行う実際の展示と並んで、ネットワーク経由での展示に力を入れている。蓄積した資料をインターネット経由で世界中から一瞬に検索したり、いろいろな所で同時に利用できる。
さらに、電子化の際に各種関連情報を統合してマルチメディア・データベース化しているので、音声や動画はもちろん、三次元データなどもネットワーク経由で入手できるようになる。そのため立体物上の距離を測るといったこともネットワーク経由で行うことが可能となる。ヴァーチャル展示により資料の価値は格段と高くなり、これらの資料を利用した研究を促進させることになろう。
このような技術革新、インフラストラクチャの整備に伴って、貴重で有用な資料をネットワーク経由で積極的に公開することは、世界に対する貢献であり、意義深いことである。
文字資料のデジタル化
このようなデジタル・ミュージアムの機能を活かすには、資料のデジタル化── すなわち最初に述べたデジタル・アーカイヴが行えることが前提
である。
そこで、ここでは文字資料のデジタル化について考えてみよう。後世に書かれた解説文などの文字情報は、多くの場合テキスト・データとしてのみ保存する。これに対して、古文書はページ全面をまず絵としてデータ化するのが前提である。書き込みをはじめとして、筆跡、字の崩し方、さらには墨の濃さまで、紙面全体が研究の対象となるからである。
だが、文章である以上、古文書であっても並行して文字を識別してテキスト・データに変換する必要もある。テキスト・データ化することによって、特定の単語を検索することもできるし、筆者の言葉の使い方を統計分析するといったこともできる。コンピュータによる音声読み上げも可能になる。古文書一冊分を図版で送る場合に比べ、テキスト・データならば数百分の一以下のデータ量になり、ヴァーチャル展示においてもネットワークに負担がかからない。また、テキスト・データであればこそ、一部を抜き出して、論文に引用したりといったことも可能になる。
文字コード
テキスト・データとは、文字コードの並びからなるデジタル情報である。コンピュータは基本的には数字しか扱うことができないから、文字も数字に変えて処理する。つまり文字コードは文字の背番号である。この背番号を指定すれば文字が決まり、いくら似ている字があってもコンピュータは間違えることはない。
どの文字にどのコード(背番号)を振りあてたかを表にしたものが、文字コード表であり、文字コード表を共有しているコンピュータの間では、背番号を送るだけで相手のコンピュータに文字情報を誤り無く伝えることができる。このように文字のデジタル化には文字コードが必須であるが、逆に言えば文字コード表に登録されていない文字はデジタル化できないということになる。いわば文字コードはデジタル時代の活字母のようなもので、活字母にある文字は使えるが、活字母にない文字は使えないということになる。ちなみに、活字の場合は必要になれば作るということも可能で、紙に印刷してしまえば元からある活字もその場で作った活字も区別はない。ワープロの場合も同様に文字コードにない文字をユーザが作り、未使用の文字コードに割り当てて、印刷する事ができる。これを外字という。
紙への印刷を前提とした場合、このような外字を使うことは問題ないが、先に述べたように、データベースに登録した資料を多くの人がネットワーク経由で利用するという場合、外字は使えない。なぜならば、外字は個々のワープロやコンピュータでしか認識されない──いわば方言だから、ネットワーク
経由で不特定多数に送るデータには使えないからである。
デジタル化できない文字
そこで、文字資料をデジタル化する場合、文字コード表に必要な文字がすべてあるかということが問題となる。現在コンピュータで広く使われている日本語向けの文字コードはすべてJISのものをベースにしているが、JISは通産省が決めた工業規格であり、基本的には現代文を記述するためにしか考えられていない。また、当時のコンピュータの限られた計算資源を有効に使うために、必要最小限の漢字に制限するという姿勢で決められている。
コンピュータの計算資源が豊かになり、現在のたいていのコンピュータはJIS第二水準までサポートしているのが普通だが、それでも六千三百五十五字しか使用できない。そのため、例えば雨月物語の最初のページ(挿図1)をJIS第二水準まででデジタル化すると次のようになる。

挿図1 |
- 雨月物語巻之一
白峯
あふ坂の関守にゆるされてより。〓こし山の黄葉見過しがたく。濱千鳥の跡ふみつくる鳴海がた。不盡の高嶺の煙。浮嶋がはら。清見が関。大礒小いその浦〓。むらさき艶ふ武蔵野の原塩竃の和たる朝げしき。象〓の蜑が笘や。佐野の舟梁。木曽の桟橋。心のとゞまらぬかたぞなきに。猶西の国の哥枕見まほしとて。仁安三年の秋は。葭がちる難波を経て。須磨明石の浦ふく風を身にしめつも。行〓讃岐の真尾坂の林といふにしばらく〓を植む。草枕はるけき旅路の労にもあらで。観念修行の便せし庵なりけり。この里…
「〓」が表現できなかった文字(挿図2)である。これではせっかく文字資料を風化から守るためのデジタル・アーカイヴが、資料を虫食いにしてしまうことになる。
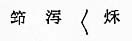
挿図2 |
多国語処理
さらに、ネットワーク経由でのデータ利用ということを考えた場合、日本以外のコンピュータからの利用も考えなければならない。この場合、漢字を含む日本語のための文字コード表は日本のコンピュータでしか使われていないため、外国のコンピュータでは個々の国語の文字コード表で解釈し、雨月物語もまったく無意味な文字列に化けてしまう(挿図3)。逆に、海外の文字資料のデジタル化の場合には、日本語のための文字コード表では表現できない文字がでてきてしまう。

挿図3 |
ユニコードまたはISO10646-1
このような問題を解決するものとして提案されたのがユニコードである。ユニコードはマイクロソフト社などの米国コンピュータ・メーカーが世界中の文字を単一の文字コード表で表現することを狙って作った規格であり、これをベースにISO(国際標準化機構)で国際規格として採択されたのがISO10646-1である(1)。しかし、このユニコードもその基本的な考え方がJISと同様で、限りあるコンピュータ資源を前提に文字を制限しようとしている点で、デジタル・アーカイヴには適さない。実際、米国コンピュータ・メーカーにとって、単一の文字コードで世界中の市場に向け開発が可能という、マーケッティング的なメリットを優先したものになっているため、デジタル・アーカイヴ応用以外でも多くの問題が指摘されている。しかし、実質的に世界のほとんどのコンピュータを支配している米メーカーがユニコード支持を表明したため、ISOも押し切られた形でそれまで検討していた案を捨てて、ユニコードとほとんど同じISO10646-1が可決されたのである。
ユニコードの問題点
ユニコード・ベースの文字コードの問題はいろいろあるが(2)、本質的な問題は、本来16ビットで表現できる文字数(六万五千五百三十六字)に入りようもない世界の文字を、その中に詰め込むために多くの無理をしているということである。その詰め込みを可能するトリックが、ユニフィケーションである。ユニフィケーションは本質的に同じシンボルなら言語の枠を越えて一つにまとめてしまおうという乱暴なものである。これによって、16ビットの枠内に世界のほとんどの言語のための文字を納めることができるというのである。しかし、今まで文字学の成果として、消滅した文字を含めれば約四百種類の文字セットが世界中で知られており(3) (4)、これをたった16ビットで表現するのはそもそも無理がある。漢字では特にこの影響が大きく、中国、台湾、日本、韓国の国内規格の合計八万千六百三十五文字からの中から五万四千十五文字を選び、さらに由来が同じあるいは多少の違い無視して二万九百二文字に統合するということが行われた。しかも元になったこの国内規格も十分なものではない。例えば、日本最多の収録字数の大漢和辞典には約四万九千字収録されているし(5)、中国の漢字にいたっては、現在編纂中の漢字辞典に六万字以上収録されているといわれる。
結局、ユニコードの文字割り当てのあらゆる基本ポリシーがその理想から外れ、単に文字セットを小さくするという基準で制定されることとなった。しかも、その妥協と無理の仕方がラテン語圏(さらにいえば英語圏)の人間のセンスで行われているため、我が国のような大規模文字集合を使う国や、彼らにとって縁の薄い東南アジア諸国の文字セットの扱いに非常に不満が多いという結果になっている。
例えば、日本語と中国語や韓国語の間では、明らかに見た目が異なる漢字までルーツが同じということで無理やり同一コードにユニファイしている例がいくつもある(挿図4)。そして何よりも、これだけ無理をして詰め込んでも、文字が足りないというのが、致命的問題である。例えば、多くの地名、人名等の固有名詞で使われながら、ない文字がある。最も簡単な例としては、日本人の人名でよく使われる「吉」の字があげられる。人名では「吉」の字の上が「土」と「士」を区別して使われるが、従来のJISコードはもとより、ユニコードでも上が「土」の吉は使えない。例えば、先の雨月物語の例でも、特にユニコード批判のために選んだ部分ではないにもかかわらず、最初のページから「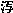 」のようにない文字が出てくる。また、表示するコンピュータによって「 」のようにない文字が出てくる。また、表示するコンピュータによって「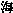 」や「 」や「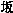 」のように中国文字の字形に引きずられてしまう文字もでてくる(挿図5)。 」のように中国文字の字形に引きずられてしまう文字もでてくる(挿図5)。
 |
 |
| 挿図4 |
挿図5 |
言語情報の必要性
また、言語の枠を超えてユニフィケーションしている以上、一度ユニコードに変換してしまうと、その文字の所属する文字セットの情報は失われてしまうというのも大きな問題である。
文字コードだけで文章が正しく表現されるわけではない。例えば日本語の禁則処理のように、文章を正しく表現するための様々な正書規則がある。どの正書規則使うか決定するためには、使用する文字セットの決定だけでなく、それが何の言語で書かれた文章であるかの情報が必要である。その情報がなければ、文面を正しく表記することはできないし、並べ替えもできない。スペル・チェッカを使う場合などでも、言語がわからなければ、単なるスペル・ミスなのか、フランス語の引用なのかの判別がつかない。また、マルチメディア・プレゼンテーションのために文章情報を音声合成により読み上げさせる場合にも言語情報が必須である。また、解説文章の自動翻訳もデータに言語情報がなければ不可能である。
さらに、インターネットのような世界規模の通信環境を考えた場合、WWWブラウザのような一つのアプリケーションで、送られてくる各国語のデータを正しく表示することが求められる。このため、送られてきたデータが、なんの言語で書かれた文章であるか、データから判別できるように ── それも、同一
文中での混在使用まで含めて、判別できるようになっている必要がある。
デジタル・ミュージアムのための文字コード
このように既成の文字コードに多くの問題があるため、東京大学デジタル・ミュージアムとして、以下のような目標で新しい文字コード体系を開発しそれを利用することを目指している。
・外字を必要としないシステムとする
・全世界、古今東西のあらゆる文字を取わ扱えるようにする
・使用されている言語が判別できるようにする
TRONコード
このような理想を満たすために開発中なのが、筆者がリーダーとなっているTRON(トロン)プロジェクト(6)の文字コード体系であるTRONコード(7)である。TRONプロジェクトは、最新の技術水準を前提とLて、理想的なコンピュータ体系を再構築することを目指すプロジェクトである。
現在このTRONプロジェクトに基づいて作られた純国産のパーソナル・コンピュータ用のオペレーティング・システムとしてBTRONがあり、その上でTRONコードが一部使用できる。現在動作しているBTRONコード環境では、補助漢字まで含む日本文字に加え、中国、韓国、そして点字が混在利用できる。TRONコード環境ではユニコードと異なり、各国の字形の異なる文字を別々に収容しているため、中国語と日本語を混在利用しても、言語の情報を失わないし、国語を混在してもそれぞれの国の字体で正確に表示される。例えば、雨月物語の例も、完全に表現できる(挿図6)。

挿図6 |
補助漢字は一九九〇年に、コンピュータの計算資源が豊かになったことを前提にJISで追加的に決められた五千八百一字の漢字である(残念ながら、BTRON以外のほとんどのオペレーティング・システムではサポートしていない)。
しかし、この補助漢字でもまだまだ足りない文字があり、現在『諸橋大漢和辞典』と『漢語大辞典』を基準に、国字を採集する作業を東京大学文学部との協同で開始している。漢字を収集し割当をしていく優先度は次の通りである。
・JISになく、国語辞典等にある文字
・以上になく、人名・地名で使われる文字
・その他流通している俗字等
・それ以外で大漢和辞典にある文字
・歴史的に使用されたそれ以外の文字
文字データベース
さらにTRONコードで特徴的なのが、単に固定的な文字コード表で、文字コードを規定するのではなく、文字データベースを介してコードとしての単一性と、表現時の多様性を両立させようとしていることである。TRONコードでは、文章記述と文字表現を分離し、二層で考えている。文章記述とはテキスト・データ中で文章が文字コードでどのように.記述されているかであり、文字表現とはその文章記述を実際に文字で印刷あるいは表示するときにどのように表現するかということである。
例えば、合字の取り扱いで考えると、テキストとしてはあくまで「f」と「i」の二つの文字が、文字表現では状況により二つの文字としたり「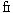 ]の一つの合字で表現される。従って文章記述と文字表現を分離して考えることが重要である。なぜならば、「…fi…」で検索したときに「…fi…」も「……」も検索されるべきだからである。そこで、TRONコードでは、文章データとして蓄積するのは文章記述であり、文字表現は表示や印刷の時にデータベースの情報をもとに文章記述から変換されるとしている。 ]の一つの合字で表現される。従って文章記述と文字表現を分離して考えることが重要である。なぜならば、「…fi…」で検索したときに「…fi…」も「……」も検索されるべきだからである。そこで、TRONコードでは、文章データとして蓄積するのは文章記述であり、文字表現は表示や印刷の時にデータベースの情報をもとに文章記述から変換されるとしている。
この変換を行うときに使われるのが、文字データベースである。文字データベースは属性情報として俗字、簡略字、合字等の文字の種別、他の字から派生した異体字の場合は元の文字へのリンク、漢字の部首、画数、読み等の大規模文字集合で文字の検索に使用できる各種のキー、さらには他のコード系に対応する文字がある場合のコードなどを文字ごとに保持している。日本の漢字については、学習漢字、常用漢字等の使用制限用の漢字集合の所属情報も持つ。これにより、文字表現時に小学校三年までの文字しか使わないで表示するなどの応用も可能となる。
さらに、このような文字データベースを導入することで、どの漢字は同じ字で、どの漢字が異体字で、どれが単なるフォント・デザイン上の違いかという判断をデータベース化して、それを文字表現に活かすことができる(挿図7)。このような判断は多分に感覚的なものであり、時代によっても異なってしまう。確たる論理的規則を作ることは、うまくいかないため、どうしても全ての対応関係をデータベース化するという列挙が必要になる。
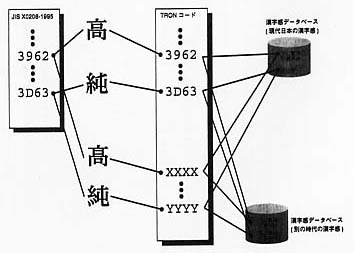
挿図7 |
このような、漢字に関する感覚の時代による変遷をデータベース化するような作業も、デジタル・ミュージアムのインフラストラクチャとして重要であると同時に、文字に関する研究に大きく役立つと考えている。
おわりに
ここであげたような問題は、古文書を扱わないユーザにとっては、関係のない問題と映るかもしれない。しかし、近年の世界規模通信環境の普及は状況を大きく変えている。WWWページの形で、従来縁のなかった多国語の文章が簡単に呼び出せるようになった。原則的に言うなら、ユーザがその言語を読める読めないにかかわらず、コンピュータとしてはそれらを当然正しく表示するべきである。
また、実用的な視点で言うならば、読めなければ読めないで自動翻訳の需要ができる。事実、日本ではインターネットの普及に伴い、WWWブラウザに組み込める自動翻訳プログラムが商品化され、新しい需要を開拓している。このようなことを考えれば、表示できるできないにかかわらず、全ての文字を言語を特定して同定できるインフラストラクチャが必要なことは明らかである。
デジタル・ミュージアムで開発しようとしている文字処理環境は、古今東西のすべての文字を登録できる基盤であり、文章記述と文字表現の二層概念の導入とその間をつなぐ文字データベースにより、効率的な処理と、人の書いたゆらぎのある文書に対する柔軟な対応を両立させる。
このような基盤の提供は、世界的な文化・学術・産業にわたり多大な貢献をするものと確信する。
88a[不掲載]デジタル活字フォント
総合研究博物館作製(協力=文学部+大日本印刷株式会社)
超高精細デジタル・ディスプレイ |
88b[不掲載]ヴァーチャル・ブック
タッチ・パネル式
総合研究博物館作製 |
89[不掲載]Internet Typography Museum (Authoring by Thimothy Campbell)
タッチ・パネル式 |
【註】
(1)日本工業規格「国際符号化文字集合(UCS)−第一部 体系及び基本多言語面」日本規格協会、一九九五年[本文へ戻る]
(2)K. Sakamura,“Multilingual Computing as a Global Communications Infrastructure,” Proc. of the Twelfth TRON Project Symposium, IEEE Computer Society Press, 1994, pp. 2-14.[本文へ戻る]
(3)Kenneth Katzner, The Languages of the World, Routlege & Kegan Paul, 1986.[本文へ戻る]
(4)Akira Nakanishi, Writing Systems of the World, Charles E. Tuttle Company, Inc., 1980.[本文へ戻る]
(5)諸橋轍次『大漢和辞典 修訂版』、大修館書店、一九八六年[本文へ戻る]
(6)K. Sakamura, “After a Decade of TRON, What Comes Next,” Proc. of the Eleventh TRON Project Symposium, IEEE Computer Society Press, 1995, pp. 2-16.[本文へ戻る]
(7)K. Sakamura,“Multi-Language Character Sets Handling in TAD,” TRON Project 1987 (Proc. of the Third TRON Project Symposium), Springer Verlag, 1987, pp. 95-111.
坂村健「TAD言語環境と多国語対応」、TRONプロジェクト'87−'88、パーソナルメディア、一九九二年、一三三〜一五〇頁[本文へ戻る]
|
|