− Ken Sakamura −
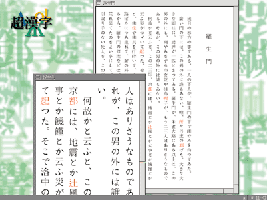
"Rashomon" displayed on Cho-Kanji that implements the TRON
Characters shown in red are outside the level-1,
and level-2 JISstandard. The TRON multi-character sets
environment makes it possible to display these characters.
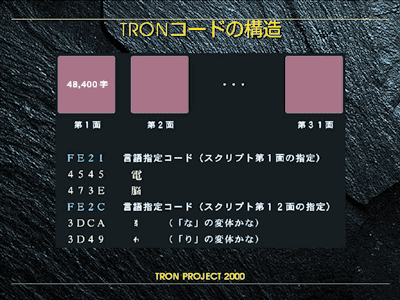
The TRON multilanguage environment refers to the stipulations and processing environment concerning the characters of the TAD (TRON Application Databus : rules for facilitating exchange of high-level application data) of the TRON project which was created to enable computers to handle all characters. Here the character code portion is simply referred to as TRON code, and this is one of the solutions that solves the problems with multilanguage/multi (kanji) characters and character codes of the previous paragraph. TRON has 31 planes, each of which can accommodate 48,400 characters. The system switches between these planes, and is capable of storing a total of approximately 1.5 million characters (which can be further extended), which means it effectively has enough capacity to store all characters. With regard to the matter as to whether a system (OS) that handle such a huge number of characters is realizable, Cho-kanji (Ultra-kanji) *1 has already been developed which has fonts with 130,000 characters installed and uses the TRON code system in accordance with BTRON specifications. It is operating extremely quickly *2. In other words, this has proven that the TRON code system is capable of handling a large number of fonts without any problems.
The 130,000 characters installed, as shown in Table 1, encompass the character code standards from various countries, approximately 50,000 characters found in Dai-kanwa-jiten (large kanji dictionary) *3, the character set of Konjaku - Mojikyo *4, including other kanji, Bon-ji (Sanskrit letters) and inscriptions on bones and tortoise carapaces , and Unicode *5 (excluding CJK unified ideographs and Hangul syllables) characters, and these characters can be mixed together when they are used. There are also plans to incorporate the character set of some 64,000 characters which is currently being prepared by the GT Project *6 being advanced by the Japan Society for the Promotion of Science and the Faculty of Literature, University of Tokyo.
TRON code allows duplicated characters, in line with its policy of incorporating multiple character sets. This is because individual character sets have their own collection policies and approaches to inclusion, which effectively makes it impossible to objectively decide on whether two particular characters are the same or different. These approaches also differ according to region and era. TRON therefore adopts the approach that it is better to assign individual numbers to the characters of multiple character sets and manage them as a database, and the development of such a database is being advanced with the name character-sensitive database. By using the character-sensitive database it becomes possible to search for the two characters as one, or differentiate them then search.
|
The structure of the TRON character code |
|