− Noboru Koshizuka −
Digital museum is required to preserve huge amount of academic material data and to provide them in the familiar form with many users. To meet the requirement, database technology is necessary. Database technology has a long history as computers. This article shortly describes recent progress of database technology focusing on multimedia databases, distributed databases, and full-text retrieval databases.
Multimedia Database
Fig.1 Multimedia Database

Conventional databases can handle only text and numerical values, and they provide query functions based on string matching and comparing numerical values. Recently, multimedia databases were developed to handle images, video, and sounds. They allow users to retrieve data by using the feature of stored images and/or sounds. For example, users can retrieve image data of ocean views, and/or image data with mountains.
Distributed Database
While a conventional database allows distribution of retrieval terminals that are connected to the databases with computer networks, the database itself is centralized in one place. In recent years, so-called distributed database was developed, which enables integrated searching among independent multiple databases distributed over computer networks. This approach is very effective because central management of very large database is unrealistic today in terms of data capacity and intellectual rights of data contents. This provides a virtually integrated large database by combining multiple small databases.
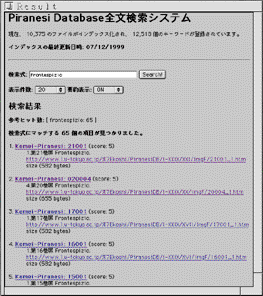
Full-text Retrieval Database
In conventional database, "schemas" are used in defining formats of data. For example, it defines that the name field of the material data record should be strings less than forty characters, and that its identifier field should be a decimal number with eight digits. Basically, pre-defined schemas restrict all data record formats, and irregular data formats are never allowed.
The most serious problem of this "schema"-based database is that, in building a large database by using existing digital data, it costs much to adjust data format of the existing data into the database schema. For example, today, there are a large amount of digital contents described in HTML and/or XML, however conventional databases do not provides search functions for this semi-formatted data.
To solve this problem, full-text retrieval databases were developed. This kind of databases can search a text data including a specific string in a large collection of non-formatted plain texts or HTML/XML texts. The main advantage of this database is that it requires no "schema" so that data creators do not have to adjust data according to database schema.
Fig.2 Full-text Retrieval Database