− 坂村 健 −
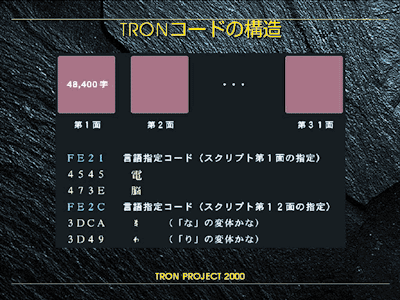
TRON多国語言語環境は、あらゆる文字をコンピュータで扱えるようにという方針でつくられたTRONプロジェクトの高水準データ交換規約TAD (TRON Application Databus) の文字に関する規約と処理環境を言う。ここでは簡単に文字コードの部分をTRONコードと呼ぶが、これは前項の「多国語・多漢字と文字コード」にある問題点を解決する一つの解である。TRONコードは48,400字入る面を31面持ち、これを切り替えて使う方式で、合計約150万字の文字を収容でき(さらに拡張も可能だが)、事実上あらゆる文字を収容するのに不足はないといえる。また、これだけの多文字を扱えるシステム (OS) が実現可能かという点についても、既にBTRON仕様に基づきTRONコード体系を利用し、13万字の文字フォントを搭載した「超漢字」*1が開発されており、きわめて軽快に稼働*2している。すなわち、TRONコード体系が実用上全く問題なく多文字を扱えることを実証した。
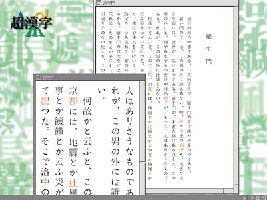
TRON多国語言語環境を実装した超漢字による「羅生門」
赤字はJIS第一第二水準にない文字。
TRON多国語言語環境ではこれらの字も表示できる
13万字には表1のように各国の文字コード規格、大漢和辞典*3掲載の約5万字およびそれ以外の漢字、梵字、甲骨文字などを含む今昔文字鏡*4の文字セット、Unicode*5(CJK統合漢字とハングルシラブルは除く)の文字を収容していて、これらの文字が混在して使える。また日本学術振興会と東京大学文学部が協同で進めているGTプロジェクト*6により整備中の6万4千余字の文字セットも収容予定である。
TRONコードでは、複数の文字セットを収容するという方針を取っていて、重複した文字を許している。これは各文字セットは夫々の収集方針や包摂に対する考え方を独自にもっているため、ある二つの文字が同じなのか違うのかは客観的に決めることは事実上不可能である。またこの考え方は、地域や時代により変化する。従って、TRONでは複数の文字セットの文字を別々の番号で割り付け、データベースにより管理する方式が優れていると考え、文字感データベースと命名してその整備を進めている。文字感データベースを使うことにより、二つの字を同じとして検索したり、区別して検索したりが可能となる。
| *1 | パーソナルメディア (http://www.personal-media.co.jp) より入手可能。DOS/V機上で動作する(Windowsが動作するのと同じパソコン上で、ディスク領域を区切って登録する)OSおよび各種アプリケーションが同梱されている。 |
| *2 | 例えば現在ではローエンドといえるPentium 166MHzのPCでも実用上全く問題なく稼働する。起動もシステムブートから15秒で立ち上がる。 |
| *3 | 諸橋轍次著 大修館書店刊 |
| *4 | 株式会社エーアイ・ネットが著作権を所有し文字鏡研究会がフォントを配布している (http://www.mojikyo.gr.jp) |
| *5 | The Unicode Consoritium |
| *6 | 日本学術振興会未来開拓学術研究推進事業「マルチメディア通信システムにおける多国語処理研究プロジェクト」 |
|
TRONコードの構造 |
|