
− Ken Sakamura −
Characters unified into single code point in UNICODE.

Level-1 and level-2 JIS standard characters in literary works.
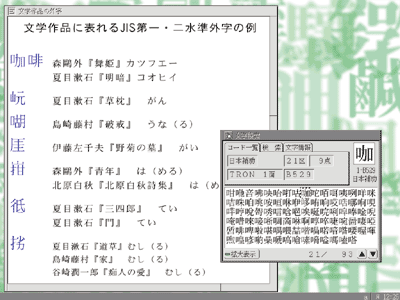
These characters could only be displayed by user-defined character
code area. Such usage makes the data interchange difficult.In many cases the scope of information handled by museums covers a wide range both temporally and spatially. For example, because the University Museum, the University of Tokyo is a public cooperative institutions of the University of Tokyo, it encompasses information in all fields over the world from the creation of the earth to modern day. The Digital Museum Concept involves not only digitizing tangible information and photographs, but also storing related information on a computer as a database. This is referred to as a digital archive, and once such information is put into a digital archive, it becomes possible to utilize this information in diverse ways, such as using it to plan and display within the museum, and using it from inside and outside the university.
In the process of digital archiving, text data is input into computers, but a major problem is encountered here.
For computers to handle text data, they assign numbers (character codes) to each character. On general computers and workstations Japanese character codes are created in accordance with character codes established by Japanese Industrial Standards (JIS). Since this standard was first created in 1978, it has undergone several revisions to reach the current JIS X0208-1997, which contains 6,355 kanji characters. This number of characters seems greater than the 1,945 characters in the table of characters for everyday use (joyo-kanji), but many characters are still encountered which are not included but required to input documents including old character types from the 1940s and earlier.
In subsequent years JIS X0212-1990 was established to include 5,801 kanji characters referred to as supplementary characters, but problems are experienced in the operating systems (OSs) used in many computers (because these OSs are created based on English, dramatic expansions in the number of characters cannot be accommodated, meaning that these auxiliary characters can hardly be used at all. To counter this problem JIS X0213, referred to the 3rd level and 4th level of JIS was established on January 20, 2000. However, the computer world is moving towards Unicode, formulated mainly by major US computer manufacturers. Unicode was created with the aim of handling all characters in the world with a single character code, and originally it was formulated as a 16-bit code due to its convenience for computer processing. Therefore the theoretical maximum number of characters that it can include is 65,536. It is therefore unable to accommodate all of the characters put forth as candidates by China, Korea, Japan, and Taiwan, and the characters were integrated to approximately 20,000 characters using the method of unification. This method involves giving a single number to similar characters with the same roots, without discriminating between character forms that have changed in individual countries, and the resultant characters are referred to as CJK unified ideographs (with CJK being the first letter of China, Japan and Korea).
When considering a digital archive, Chinese, Japanese and Korean characters are often mixed with one another, and there are great problems in archiving in Unicode, which mixes them up. This is because it is easy to handle as one unit information that has been separated by a computer, but it is impossible to separate information that has been integrated into one.
To resolve this problem, The University Museum, The University of Tokyo is using the TRON multi-language environment developed by the TRON project. Readers should refer to other sections for more details on this environment.
